Featured Projects

Projeto Implementando um Data Warehouse On Premises
- Featured Skills
O primeiro passo do meu projeto é olhar com o lado do consultor vamos implementar um DW, mas também vamos entender as necessidades do Cliente sempre utilizando as melhores práticas do PMI (Project Management Institute) para gestão de projetos e ITIL (Information Technology Infrastructure Library) que são boas práticas e focam em alinhar os serviços de TI com as necessidades dos negócios. Estamos passando por cada passo. Sessão de captura de conhecimento com gestores, pesquisa de exigências com analistas funcionais e definição de arquitetura com equipe de TI.
Check it out
Implementando um Data Warehouse na nuvem com AWS
- Featured Skills
Seria possível montar um Data Warehouse para armazenamento e processamento de petabytes de dados em apenas alguns cliques? A resposta vou deixar para vocês verificar o meu projeto!!!
Check it out
Carregando dados de streaming no cluster Redshift
- Featured Skills
Vou tomar como base que você viu o Project Data Warehouse em Nuvem com o Amazon Redshift, aqui vou explicar de forma rápida e direta como executar uma carga de dados em tempo real (streaming de dados) A AWS oferece algumas soluções que nos permitem executar esse tipo de tarefa. Usarei o Amazon Kinesis Data Firehose que permite consumir, buffer e processar dados de streaming em tempo real, fornecendo insights em segundos ou minutos em vez de horas ou dias. Lembre-se de verificar os termos e preços de qualquer produto AWS!
Check it out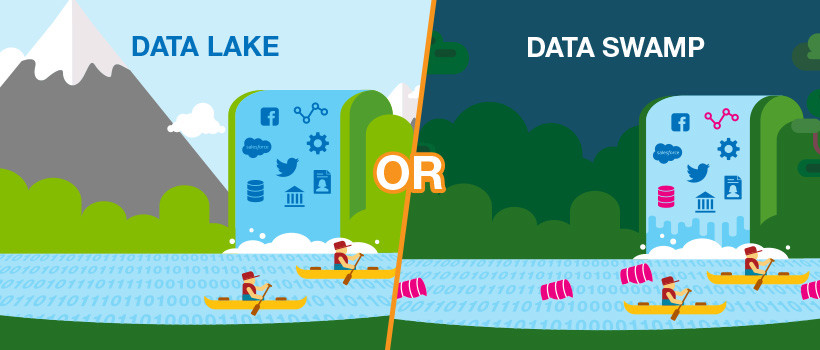
Implementando um Data Lake On-Premises
- Featured Skills
Esse projeto tem como base implementar um Data Lake do zero On-Premises e buscar entender o conceito de Data Lake e principais diferenças de um Data Warehouse
Check it out
Alta Disponibilidade em Streaming de dados Transacionais
- Featured Skills
Alta Disponibilidade dos dados utilizando Golden Gate com dois cenários o primeiro será Streaming de dados Transacionais entre 2 Database e no cenário 2 a replicação entre Banco Relacional e o HDFS.
Check it out
Alta Disponibilidade no Data Lake
- Featured Skills
Configurando Data Lake com Alta Disponibilidade com o ambiente de Cluster Hadoop .!
Check it out
Configurando Segurança no Cluster Hadoop Data Lake com Kerberos.
- Featured Skills
Como engenheiro de Dados, precisamos aprender como implementar políticas de autenticação, autorização e auditoria para acessar e usar dados armazenados no cluster Hadoop, bem como proteger os dados em trânsito e em repouso. Essa é a parte 2 do projeto. Na primeira instalamos e configurando um Data Lake com cluster Hadoop e nesse segundo projeto implementamos Segurança com Kerberos.
Check it out
Auditoria no cluster Apache Hadoop.
- Featured Skills
O objetivo desse projeto é mostrar a configuração de auditoria no cluster Hadoop seus conceitos e vamos discutir e compreender um pouco sobre outras ferramenta de segurança como Apache Knox, Apache Range e Apache Sentry suas diferenças e qualidades.
Check it out
Teste de Penetração (PENTEST) .
- Featured Skills
Esse Projeto tem como base melhorar a segurança do meu Data Lake. Testar as portas e verificar falhas de segurança e as vulnerabilidade do ambiente Hadoop.
Check it out
Deploy de Modelo de Machine Learning com comunicação gRPC e Docker.
- Featured Skills
Basicamente nós vamos desenvolver um modelo de Machine Learning que vai realizar previsões quando receber novos dados. O Docker vai ser nossas ferramentas de Deploy, no docker nós vamos fazer a implementação de um modelo de machine learning para isso vamos usar python e Scikit-learn. Uma vez que o modelo estiver pronto ele vai receber requisição, vamos passar dados para o modelo e ele vai devolver previsões como resposta, mas como vai ocorrer essa comunicação? Precisamos estabelecer um Protocolo para esse caso usaremos o gRPC que é um dos principais protocolos de comunicação em arquitetura de microsserviços.
Check it out
Deploy do Modelo de Machinee Learning com TensorFlow Serving e Kubernets na nuvem Google Cloud Platform.
- Featured Skills
O Objetivo é servir um modelo de Machne Learning para reconhecimento de imagens através de Inteligência Artificial. Usaremos o TensorFlow Serving para servir o modelo em um contêiner Docker e faremos o deploy em um cluster Kubernetes para escalabilidade da aplicação, claro o foco aqui vai ser o Deploy e não o modelo, o modelo será pré-treinado e então farei todo o trabalho de infraestrutura para o deploy desse modelo. Depois que o modelo estiver pronto e disponível no container Docker então farei o deploy em um cluster Kubernets e para isso vou utilizar o Google Cloud Platform.
Check it out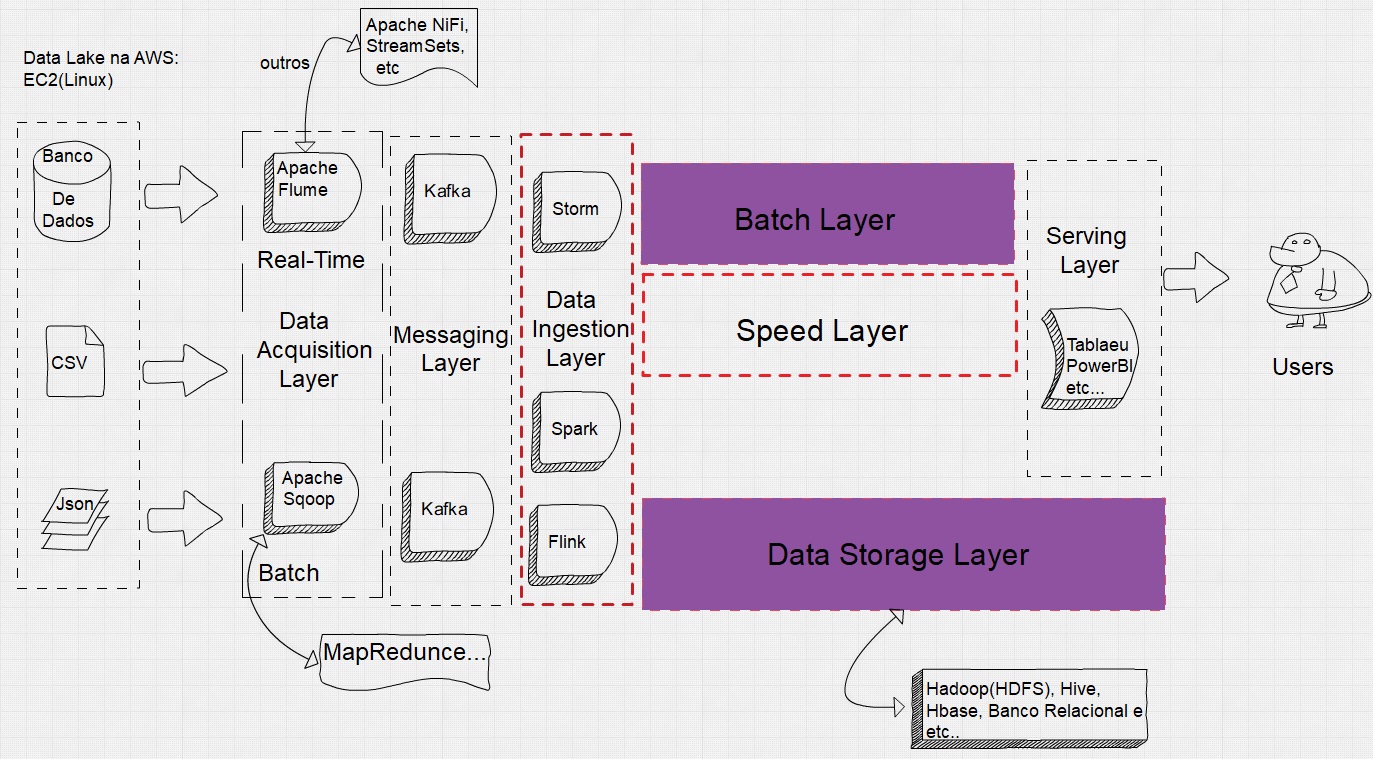
Criação de um Data Lake na Nuvem AWS.
- Featured Skills
Nesse projeto irei implementar um Data Lake utilizando cloud AWS e também irei implementar a camada de aquisição de dados em Batch com Sqoop.
Check it out
Data Lake na AWS, Aquisição de dados em Striming com Apache Flume e Apache Nifi.
- Featured Skills
Esse Projeto é uma Continuação da Criação de um Data lake na AWS, Irei implementar a Camada de ingestão de dados em Streaming com Apache Flume e Apache NiFi
Check it out
Data Lake na AWS, Camada de Mensagem com Kafka.
- Featured Skills
Esse projeto é uma continuação da Criação de um Data Lake na AWS, mas irei implementar a camada de Mensagem com Kafka, irei desenvolver o producers e consumers em Java e 2 Projeto de Pipeline com StreamSets.
Check it out
Data Lake na AWS, Camada de Persistência dos dados(armazenamento)no HDFS e manipulação dos dados com Hive e Hbase.
- Featured Skills
Esse projeto é uma continuação da Criação de um Data Lake na AWS, mas irei implementar a camada de Persistência dos dados (armazenamento) no HDFS e manipulação dos dados com Apache Hive e Apache Hbase, concluindo todo o ciclo do Data Lake de ponta a ponta.
Check it out